
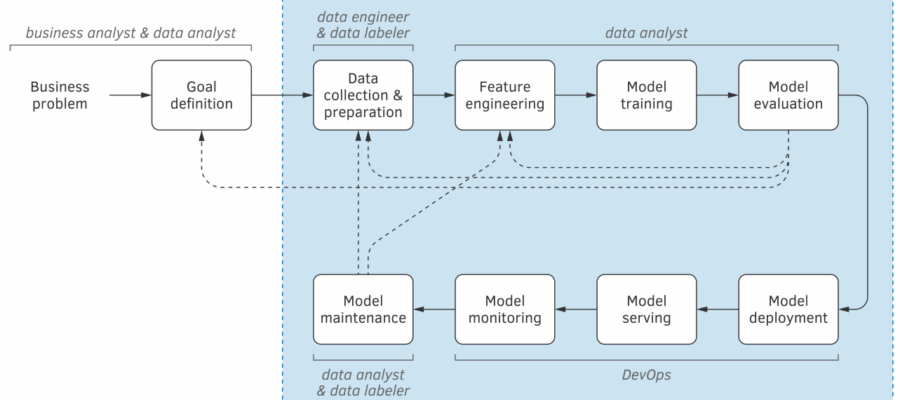
En un mundo donde los datos están en constante crecimiento y donde la demanda de análisis precisos es más alta que nunca, las técnicas de reescalado emergen como un elemento crucial en el desarrollo de modelos de machine learning (ML). La capacidad de reescalar correctamente los datos no solo mejora el rendimiento del modelo, sino que también facilita la interpretación de los resultados, algo que es esencial para la toma de decisiones. Pero, ¿qué exactamente implica el reescalado y cómo puede transformar la calidad de nuestros modelos predictivos?
En este artículo, exploraremos las técnicas de reescalado más efectivas que pueden aplicarse para optimizar los modelos de ML. Desde la normalización hasta la estandarización, cada método posee características únicas que pueden influir drásticamente en la performance del modelo. A través de un análisis profundo, examinaremos cómo y cuándo implementar cada técnica, así como sus implicaciones en el tratamiento de distintos tipos de datos. Ya sea que estés comenzando en el mundo del machine learning o que busques afinar tus habilidades, este artículo te proporcionará la información necesaria para reescalar tus datos de manera efectiva.
¿Qué es el reescalado y por qué es importante en ML?
El reescalado de datos es el proceso de ajustar los valores de las características numéricas para que se encuentren dentro de un rango específico. Este proceso es fundamental en machine learning, ya que distintos algoritmos son sensibles a la escala de los datos. Por ejemplo, métodos como la regresión logística, las máquinas de soporte vectorial y las redes neuronales pueden verse significativamente afectados por la forma en que están distribuidos los valores de entrada.
La importancia del reescalado se puede entender en varios niveles. En primer lugar, ayuda a evitar que las características con mayores rangos dominen el aprendizaje del modelo. Si una variable tiene una escala mucho más grande que otra, los algoritmos pueden tener dificultad para ajustarse correctamente a los datos. Esto puede resultar en un modelo que no generaliza bien o que tiene un desempeño deficiente. En segundo lugar, reescalar los datos puede acelerar el proceso de convergencia en algoritmos de optimización, lo que significa que el modelo puede aprender de manera más rápida y eficiente. Por último, un buen reescalado permite mejorar la estabilidad numérica de los procesos, algo crucial en cálculos que pueden llevar a errores acumulativos.
Recomendado: Diferencias entre reescalar y redimensionar imágenes gráficas
Diferencias entre reescalar y redimensionar imágenes gráficasTécnicas de reescalado: Normalización
Una de las técnicas más comunes de reescalado es la normalización. Este método ajusta los valores de las características para que se encuentren dentro de un rango específico, típicamente entre 0 y 1. La normalización es especialmente útil cuando los datos necesitan ser escalados de manera uniforme, o cuando se utilizan métricas basadas en la distancia, como el k-vecinos más cercanos. La fórmula típica para la normalización de un valor x es:
X_n = (X – min(X)) / (max(X) – min(X))
Donde X_n es el valor normalizado, min(X) y max(X) son los valores mínimo y máximo de la característica respectiva. Sin embargo, es importante mencionar que la normalización puede ser sensible a la presencia de outliers, ya que podrían influir significativamente en los valores de min(X) y max(X). Por ello, se debe tener cuidado en su implementación y considerar el contexto de los datos y las características del problema.
Técnicas de reescalado: Estandarización
Otra técnica ampliamente utilizada es la estandarización, que transforma los datos para que tengan una media de 0 y una desviación estándar de 1. Esto se logra mediante la fórmula:
X_s = (X – μ) / σ
Recomendado: Plugins eficientes para reescalado de imágenes en 2024
Plugins eficientes para reescalado de imágenes en 2024Donde X_s es el valor estandarizado, μ es la media y σ es la desviación estándar de la característica. La estandarización es particularmente beneficiosa cuando se trabaja con algoritmos que suponen que los datos son distribuciones normales. Al transformar los datos de esta manera, los modelos pueden aprender de forma más efectiva y realizar predicciones más precisas. Sin embargo, al igual que con la normalización, la estandarización también puede ser influenciada por los outliers, por lo que es esencial tener en cuenta su presencia al aplicar esta técnica.
La selección de la técnica adecuada para tus datos
Elegir la técnica de reescalado adecuada puede ser un desafío. La decisión debe basarse en el tipo de datos, la distribución de los valores y el algoritmo que se planea utilizar. Por ejemplo, si los datos presentan una distribución normal, la estandarización podría ser la opción preferida. En cambio, si hay una amplia gama de valores o si se prevén utilizar algoritmos que son sensibles a la escala, como los métodos de distancia, la normalización puede ser más eficaz.
Es vital también evaluar la presencia de outliers en los datos. Si los outliers son una preocupación, podría ser beneficioso considerar técnicas adicionales, como la transformación de Box-Cox o la transformación logarítmica, que pueden ayudar a estabilizar la varianza y hacer que los datos sean más propensos a una distribución normal. En última instancia, experimentar con ambas técnicas y utilizar técnicas de validación cruzada para evaluar el rendimiento del modelo post-reescalado es una estrategia recomendada para encontrar la mejor opción.
Impacto del reescalado en el rendimiento del modelo
El impacto del reescalado en el rendimiento del modelo de machine learning es significativo. Estudios han demostrado que modelos entrenados en datos correctamente reescalados tienden a mostrar un desempeño superior en comparación con aquellos que utilizan datos sin ajustar. Esto no solo resulta en una mayor precisión, sino que también puede traducirse en una mejor generalización a datos no vistos.
Además, las métricas de validación cruzada, tales como la precisión, el recall y la F1-score, pueden estar fuertemente influenciadas por el reescalado. Por ejemplo, un modelo que muestra una mejora del 20% en estas métricas al implementar el reescalado puede hacer una gran diferencia en aplicaciones prácticas, como clasificación de texto, reconocimiento de imágenes o predicciones financieras.
Recomendado: Guía completa sobre qué imágenes es necesario reescalar
Guía completa sobre qué imágenes es necesario reescalarConsideraciones finales sobre el reescalado de datos
Implementar técnicas de reescalado efectivas es un paso crucial en el flujo de trabajo de machine learning. No se debe subestimar la importancia de este proceso, ya que afecta no solo el rendimiento del modelo, sino también la forma en que interpretamos los resultados. A medida que el campo evoluciona y se presentan nuevos desafíos con conjuntos de datos cada vez más complejos, dominar el arte del reescalado se convierte en una competencia vital para todo científico de datos.
Por último, al considerar las técnicas de reescalado, recuerda que lo que funciona para un conjunto de datos no necesariamente será efectivo para otro. La experimentación, junto con un riguroso razonamiento basado en la teoría estadística, serán tus mejores aliados en el proceso de reescalado. Al mantener la atención en estos aspectos, podrás asegurar que tus modelos de machine learning alcancen su máximo potencial y ofrezcan resultados valiosos y significativos.